Appunti e note al bel video di Simone Rizzo: https://www.youtube.com/watch?v=M3W4FEMmOHY
“Il Futuro della Programmazione: Agent Swarm”
In questo video parliamo del futuro degli agenti AI e dei paradigmi che stanno definendo la prossima generazione di intelligenza artificiale.
1. Completion models (code completion)
Primo paradigma: completion in editor, cioè un modello addestrato a completare il codice guardando il testo precedente e suggerendo il “pezzo successivo” (snippet, funzioni, ecc.).
Nota storica: il 2018 è l’anno di svolta rispetto i completamenti funzionali; con l’introduzione di Microsoft IntelliCode e Kite, che utilizzavano l’apprendimento automatico (Machine Learning) per offrire suggerimenti più intelligenti e contestuali, analizzando repository open source come GitHub.
Nel video viene mostrato anche l’uso dell’approccio “commento → codice”, dove un commento descrittivo porta alla generazione dell’implementazione (sempre come autocompletamento di codice).
2. Chatbot generalisti
Step successivo: usare chatbot generalisti (es. ChatGPT/Gemini) per generare blocchi più grandi (script interi, classi, test), ma con workflow ancora manuale e copia-incolla nell’editor.
3. Coding agents
Passaggio chiave nel mondo della programmazione: il coding agent come modulo con LLM + tool, integrato nell’editor, capace di creare/modificare file, leggere codebase, eseguire comandi e (se previsto) fare automazioni di browser.
Esempi di coding agent: Claude Code, Codex, Cline.
Cosa è un Coding Agent: LLM + set di funzioni/tool (creazione file, lettura file, sostituzioni, comandi shell, ricerca, web search, browser automation) che permettono di lavorare su un progetto (non solo su uno snippet).
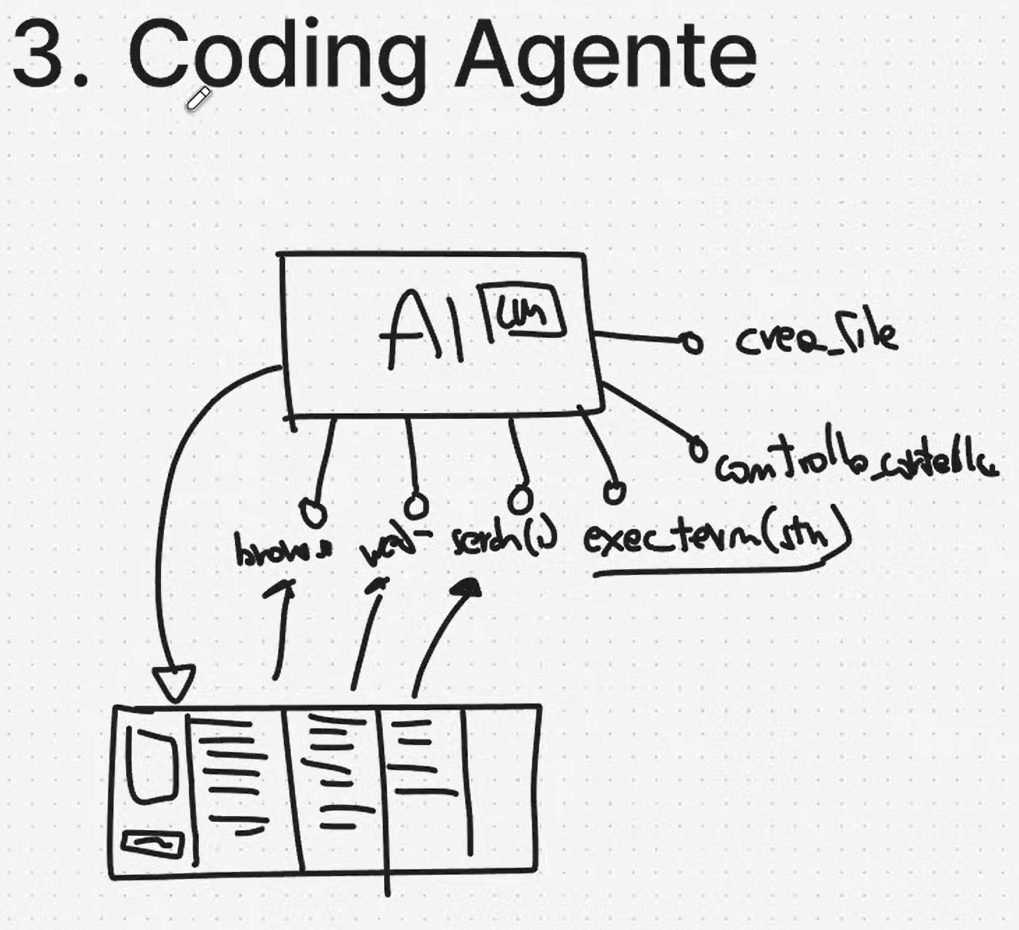
Problema 1: ovviamente non posso buttare un intero repository nella mia Context Window…
Per gestire in modo intelligente la repo i coding agent usano un sistema RAG. Vedi sotto il capitolo dedicato, ma in sintesi ciò che viene operato è: embedding / vettorizzazione delle varie parti della codebase; inserimento su un DB vettoriale; recupero delle sole parti necessarie alla richiesta dell’utente (per non saturare il contesto).
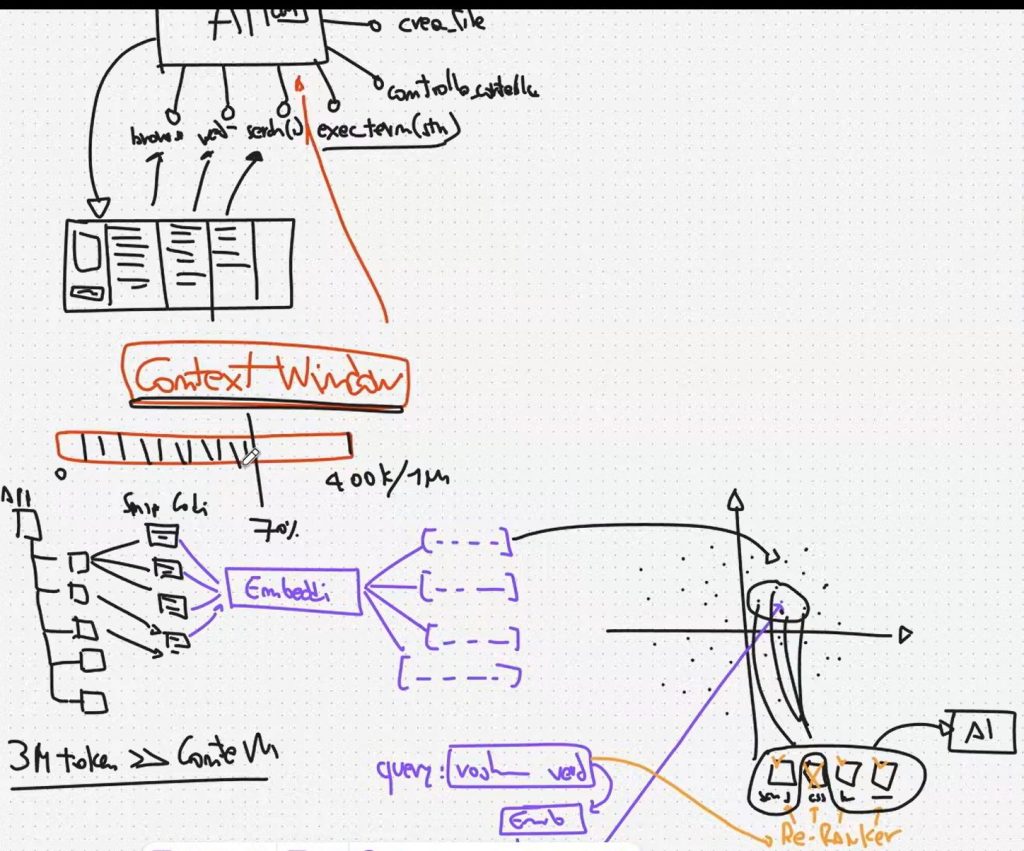
Purtroppo non basta.
Problema 2: la Contex window è limitata. Con codebase medio-grandi il contesto si satura in poco tempo. Ogni modello ha un limite massimo di token gestibili in input (400k token, fino a 1M token), ma la codebase reale può superare ampiamente questo limite.
Inoltre già riempire la Context window a metà porta a un calo di prestazioni. Questo fenomeno viene detto Context rot.
Il degrado prestazionale avviene man mano che cresce l’input: dalla metà della context window in poi il modello tende a peggiorare e commettere più errori, fino a bloccarsi/saturarsi vicino al limite
Ecco perché si esplorano strategie come multi-agent (contesti separati) e, soprattutto, agent loop (con sessioni fresche o compattazione/editing del contesto).
4. Multi-agent systems (orchestrator + sub-agenti)
Per gestire task lunghi e ridurre saturazione del contesto, viene introdotto il paradigma multi-agente: un orchestratore dialoga con l’utente e delega a sub-agenti specializzati (frontend, backend, tester, ecc.), ciascuno con una propria context window “pulita”.
Limite: l’orchestratore tende comunque a saturarsi perché accumula la conversazione con l’utente e riceve molto testo di ritorno dai sub-agenti.
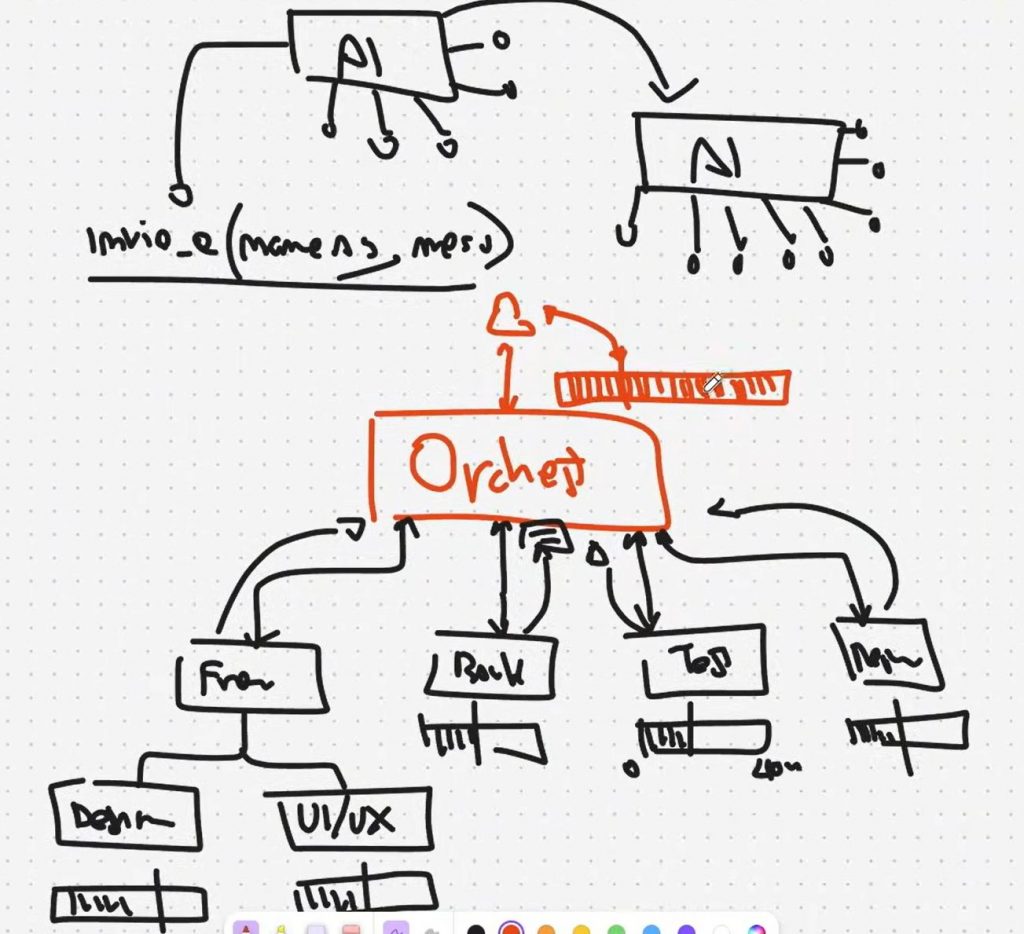
Ecco quindi che si arriva al nuovo paradigma di inizio 2026: l’Agent Loop.
5. Agent Loop (single agent, sessioni “fresh” o compaction)
- Nuovo paradigma introdotto/accelerato da Ralph: si scarta il multi-agent “classico” e si torna a un singolo agente in loop, che riparte spesso con contesto pulito e usa file di spec/progresso come memoria esterna.
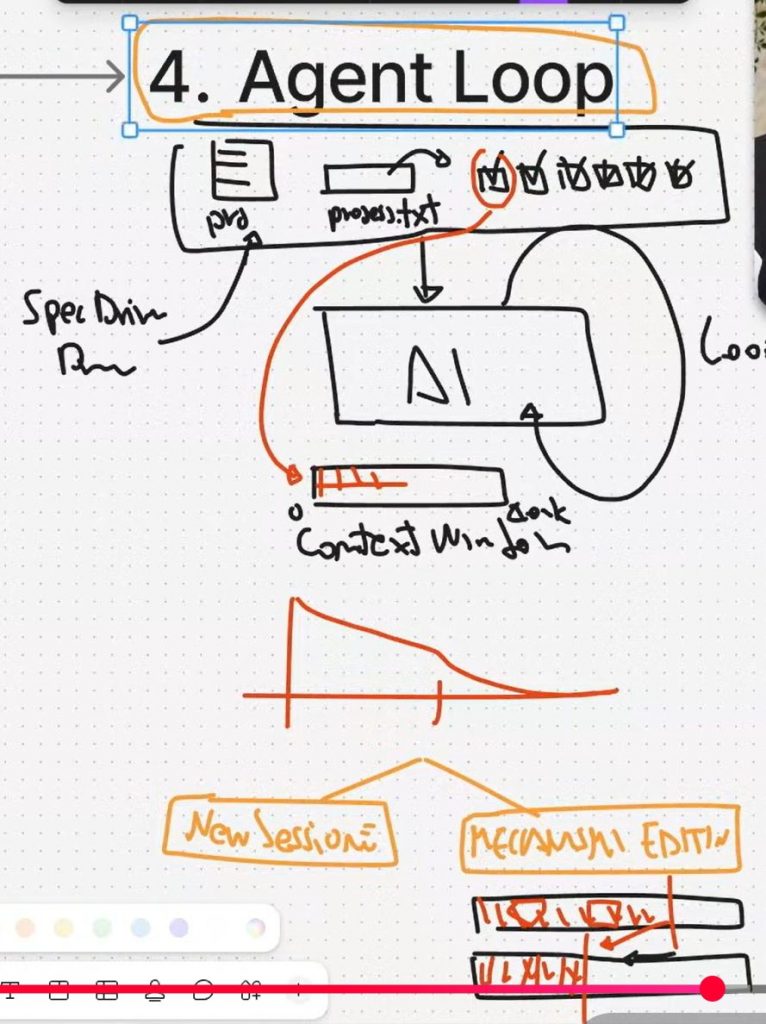
- Come funziona:
- abbiamo un singolo agente AI, che vive in un ciclo e viene chiamato ogni volta;
- tutte le volte che viene chiamato la Context Windows si pulisce oppure viene editata e sfoltita;
- l’agente tiene memoria e porta avanti le cose da fare tramite un PRD (Product Requirement Document) e un progress.txt – il PRD viene popolato all’avvio con tutte le specifiche di progetto, il progress tarrà traccia dell’avanzamento dei task;
- in sostanza l’AI Agent parte e cicla (a ogni ciclo con contesto pulito) fino a che non completa tutti gli step presenti nel progress.txt (seguendo le direttive del PRD)
- Concetto utilizzato dagli Agent Loop: Spec-Driven Development – SDD

- Altro paradigma simile a Ralph: https://github.com/glittercowboy/get-shit-done
- OpenAI Codex Agent Loop
- BMAD Method – Breakthrough Method of Agile AI Driven Development — An AI-driven agile development framework with 21 specialized agents, 50+ guided workflows, and scale-adaptive intelligence that adjusts from bug fixes to enterprise systems.
6. Agent Swarms (parallelismo + auto-creazione agenti)
- Ultimo paradigma presentato: Agent Swarm, dove un orchestratore crea automaticamente sub-agenti e assegna task in parallelo, combinando orchestrazione + parallelismo + (idealmente) loop/contesti gestiti per evitare degrado.
- Lanciato da Kimi (modello K2.5) la capacità di orchestrare fino a 100 sub-agenti e fino a 1500 tool calls, con risparmi di tempo indicati come ~4.5–5x rispetto al single-agent setup.
RAG su codebase: vettorizzazione + retrieval semantico
1) Chunking: ogni script/file viene spezzato in snippet di codice.
2) Embedding: ogni snippet passa in un modello di embedding che lo converte in un vettore.
3) Vector DB: i vettori vengono salvati in un database vettoriale (spazio dove la vicinanza rappresenta similarità semantica).
4) Query embedding: anche la query dell’utente viene convertita in vettore.
5) Semantic search: si cercano i punti più vicini (top‑k) e si recuperano gli snippet associati.
6) Re-ranking: un reranker decide quali snippet tenere/scartare, prima di passarli all’agente come contesto effettivo.
7) Prompt assembly: l’agente usa gli snippet selezionati come input, invece di leggere tutto
Nota: se l’utente indica esplicitamente file/riga/nome script, l’agente può bypassare la semantica e usare tool di ricerca mirata (file lookup/keyword) per leggere solo il necessario.
Re-ranker: ruolo e varianti menzionate
- Il reranker utilizzato nei RAG è un secondo modello che, dati query + snippet candidati, sceglie cosa includere nel prompt finale per massimizzare rilevanza e ridurre rumore.
- esistono molti reranker, come Jina reranker, bge reranker base e reranker specializzati per dominio (scientifico/medico) o per lingua (es. polacco).
Link e menzioni del video
- OpenAI Codex Agent Loop: https://openai.com/it-IT/index/unrolling-the-codex-agent-loop/
- Google Antigravity rules/workflows: https://antigravity.google/docs/rules-workflows
- Ralph Loop (repo): https://github.com/snarktank/ralph
- GSD – Get Shit Done (repo): https://github.com/glittercowboy/get-shit-done
- BMAD Method (repo): https://github.com/bmad-code-org/BMAD-METHOD
Immagine copertina: Watercolour depiction of the fly agaric, 1892. Likely painted at an art class near Bristol, England, the writing says “Agaricus muscarius” and “Leigh woods Sept/92”.
Screenshot e contenuti estratti dal video di Simone Rizzo.

In questo video parliamo del futuro degli agenti AI e dei paradigmi che stanno definendo la prossima generazione di intelligenza artificiale. Partiamo dai modelli completion, passiamo ai chatbot, ai coding agent, fino ai sistemi multi-agent, agli agent loop e infine al nuovissimo concetto di agent swarm. Spiego nel dettaglio come funzionano i coding agent, perché il problema della context window e del context rot limita le loro performance, e come i ricercatori stanno risolvendo il problema con nuovi loop e architetture. Analizziamo alcune delle soluzioni più interessanti già disponibili.