I converters in Pandas sono funzioni personalizzate che permettono di trasformare i dati mentre vengono letti da un file CSV (o altri formati). Si specificano tramite il parametro converters di pd.read_csv() e consentono di applicare delle logiche di conversione colonna per colonna, prima che i dati vengano inseriti in un DataFrame Pandas.
Funzionamento base
Il parametro converters accetta un dizionario dove
- le chiavi sono i nomi (o gli indici) delle colonne
- i valori sono le funzioni che trasformano i dati di quella colonna.
Ogni funzione riceve come input il valore della cella come stringa e restituisce il valore trasformato.
converters = {
'colonna_nome': funzione_di_conversione,
0: altra_funzione # puoi usare anche l'indice numerico
}
df = pd.read_csv('file.csv', converters=converters)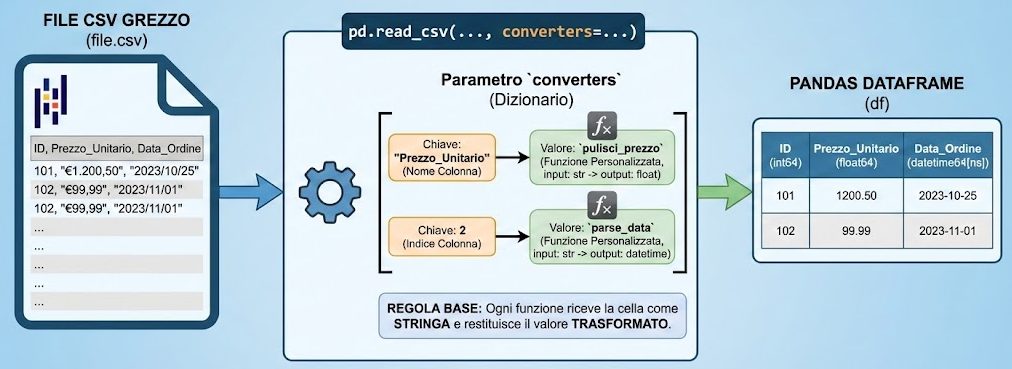
Esempio pratico
Il libro Learning Scientific Programming with Python illustra bene il concetto.
L’esempio proposto nel libro mostra come convertire dosi giornaliere raccomandate di vitamine in un formato uniforme. Il file contiene dati come “900ug/700ug” (valori per uomini e donne, per cui va calcolata media) o “1.2mg/1.1mg” (come prima, ma con unità di misura diverse).
Prima dell’import vado quindi a scrivere una funzione che applicherò alla colonna di mio interesse per:
- dividere i valori separati dal carattere
/; - uniformare le unità di misura diverse;
- calcolarne la media.
import pandas as pd
def average_rda_in_micrograms(col):
def ensure_micrograms(s):
if s.endswith("ug"):
return float(s[:-2])
elif s.endswith("mg"):
return float(s[:-2]) * 1000
raise ValueError(f"Unrecognised units in {s}")
fields = col.split("/")
return sum([ensure_micrograms(s) for s in fields]) / len(fields)
df = pd.read_csv(
"vitamins.txt",
sep=r"\s+",
skiprows=4,
skipfooter=1,
header=None,
usecols=(1, 2, 3),
converters={"RDA": average_rda_in_micrograms},
names=["Vitamin", "Solubility", "RDA"],
index_col=0,
engine="python"
)Limiti dei converters
Sul campo ho imparato a mie spese che i converters di Pandas hanno limiti di performance e scalabilità quando si lavora con dataset importati.
Performance scadenti
Il limite principale è che i converters vengono chiamati riga per riga (row-by-row) invece che in modo vettorizzato sull’intera colonna. Questo significa che se ho 1 milione di righe, la funzione converter viene eseguita 1 milione di volte invece di una sola volta su tutto il vettore (risultando anche 60 volte più lento rispetto una conversione post-lettura). Inoltre se applico il converter su n colonne… devo moltiplicare per n i tempi di elaborazione.
Conflitti con altri parametri
I converters bypassano il parsing standard, quindi parametri come decimal, na_values, e parse_dates potrebbero non funzionare come previsto sulle colonne convertite.
Come superare questi limiti – Conversione post-lettura
# Leggi prima con dtype ottimizzato
df = pd.read_csv('file.csv', dtype={'colonna': 'str'})
# Poi applica la conversione vettorizzata
df['colonna'] = df['colonna'].apply(lambda x: tua_funzione(x))
# O meglio ancora, usa operazioni vettorizzate native
df['colonna'] = pd.to_datetime(df['colonna'], format='%Y-%m-%d')La regola generale / buona pratica da ricordare è:
- OK i converters per dataset piccoli o dove non interessano performance e velocità;
- usare
dtypeper specificare tipi semplici durante la lettura; - applicare trasformazioni complesse solo dopo la lettura, attraverso operazioni vettorizzate.